
String type is a fundamental type of all programming languages. It’s also the very first language that you will learn when start programming. The String type is easy and straightforward. However, on the other hand, it is very complicated under the hood. The String type needs to handle the glyphs of various languages, the reading order of languages, and many other locale-specific behaviors. Moreover, the storage and the display of a String in the modern computer system is also a big issue. All of those are elegantly wrapped into an easy and intuitive String type.
When it comes to Swift, in Swift, the String type could be very intuitive, like concatenate Strings by using the “+” operator. It could also be very complicated, such as access a specific character in a string. Why String type is so controversial in Swift? Why can’t we use the subscript pattern to access a character in the string? How does Swift fully support the Unicode and why does it matter? In this article, we will dive deep into the fundamental of the String type, from the String Encoding to the Swift String API. After reading this article, you will learn:
- What’s String Encoding, Unicode, UTF-8, etc…
- How does Swift achieve the Unicode-compliance
- Swift String API: index, comparison, substring, etc..
- The relation between NSString and Swift String
The Swift version of the code snippets is 4.2. But except the Swift String API, the fundamental concepts are invariable within different versions.
Let’s start from the world outside Swift, back to the old good days 💾
Character encoding
As an engineer, you must be very familiar with the ASCII code. Since the computer world is composed by 0 and 1, we must have an encoding system to represent the human characters by numbers. ASCII is a good example. The character “A” is encoded by a decimal number “65”, “B” is encoded by a decimal number “66”, and so on. The ASCII can represent 256 characters, including the whole 26 alphabetic characters. In that 640k-is-enough era, it looked enough for encoding all English words. However, there are way more characters in languages other than English. The most common Korean characters is around 2,000. Not the mention the Chinese, which has over 50,000 characters. In order to make all languages in the world could be represented in the computer, we need a better encoding system. So the Unicode is here to rescue!
Before we jump into the Unicode system, let’s take a deeper look at what’s the Character Encoding. Character Encoding is a system used to represent characters by numbers. The purpose of doing encoding is because that we want to save, display, or distribute the language in the computer, and the computer can only deal with numbers. Intuitively, we can have a huge paper sheet, transcribing all characters and mark all of them with serial numbers. This huge paper sheet is called the “Code Space”. And the number assigned to each character is called the “Code Point”. Given this huge paper sheet, we can encode a paragraph of any language into a series of numbers, by looking up the Code Points for all characters in the paragraph. We can also load a series of numbers from a computer, and look up corresponding characters to decode them back to a paragraph. Briefly speaking, this imaginative huge paper sheet is the Unicode.
A single Unicode code point could be as small as 1, 2, 3…, it could also be as large as 0x1F3C2 in Hex. The storage unit of a computer is by bytes (0~255). So you might wondering, if we need to save the code point into the computer storage, how many bytes do we need for a single code point? Let’s take a look at an example:
"🏂 costs ¥"
This is a sentence with different special characters. The whole sentence can be represented by Unicode code points, as the following table:
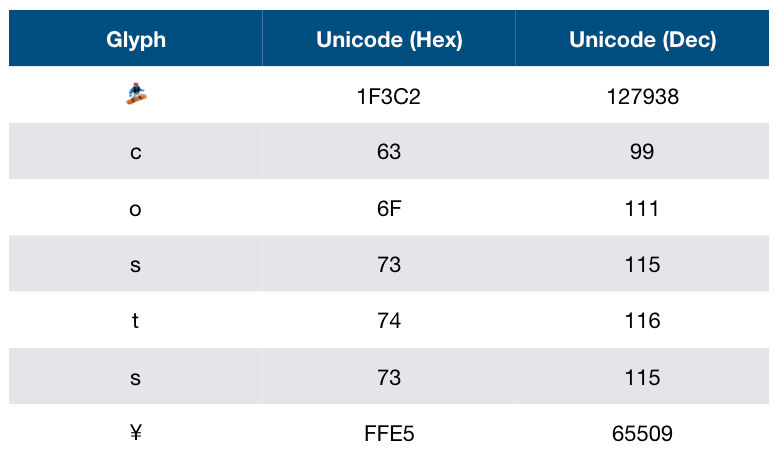
The first character, 🏂, is an snowboarding emoji. In Unicode system, the code point of it is U+1F3C2, which is a 17-digit binary number 11111001111000010.
Now, we want to store those characters into the computer. Though the code points are numbers, in order to save those into the computer system, we need find a way to convert those numbers into bytes. Remember that the largest code point has 17 digits, so a 32-bit container is a good choice. One 32-bit container can store a English character such as “c” (code point: 99), it can also store a emoji “🏂” (code point: 127938). By using 32-bit containers, we can store all Unicode code points without any conversion. On one hand, it’s convenient because we don’t need to convert any code point, on the other hand, it wastes a lot of spaces. Most of common characters’ code points are only 8-bit, use 32-bit containers to save 8-bit data will leave 24 bits unused.
Another method is to use one 16-bit container to save a code point which is smaller than 16-bit, and use two 16-bit containers to save the one larger than 16-bit. The following graph depicts the relation between the code point and the size of different storage containers:
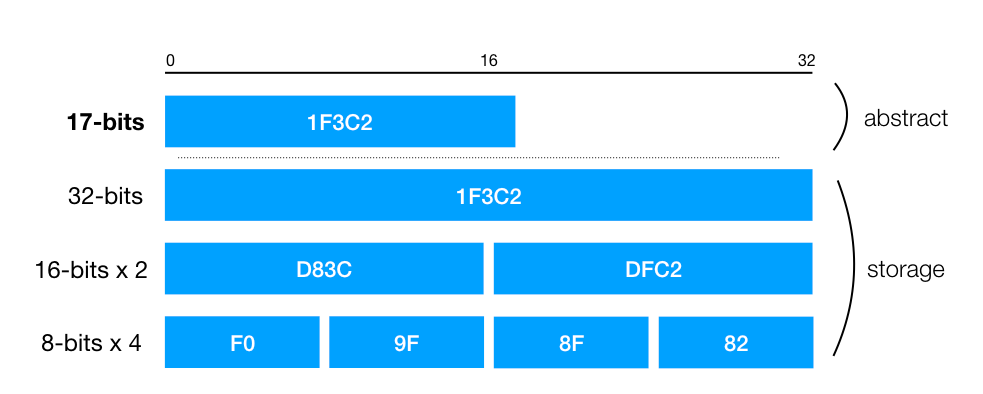
Practically, we have to store the data bytes by bytes. In this graph, the “abstract” is the Unicode code point. The “storage” section is how we break down the code point into bytes. The way we encode the code point is called Character Encoding Form, and the container unit we are using is called Code Unit. A 17-bit code point can be encoded as one 32-bit code unit, or 4 8-bit code units. And as you may guess, the 32-bit character encoding form is UTF-32, the 16-bit one is UTF-16, and the last one is UTF-8. We won’t elaborate the detail of those character encoding forms, but the implementation of those are very interesting. You can check out more details, such as size of code spaces and how supplementary planes works in the wiki page.
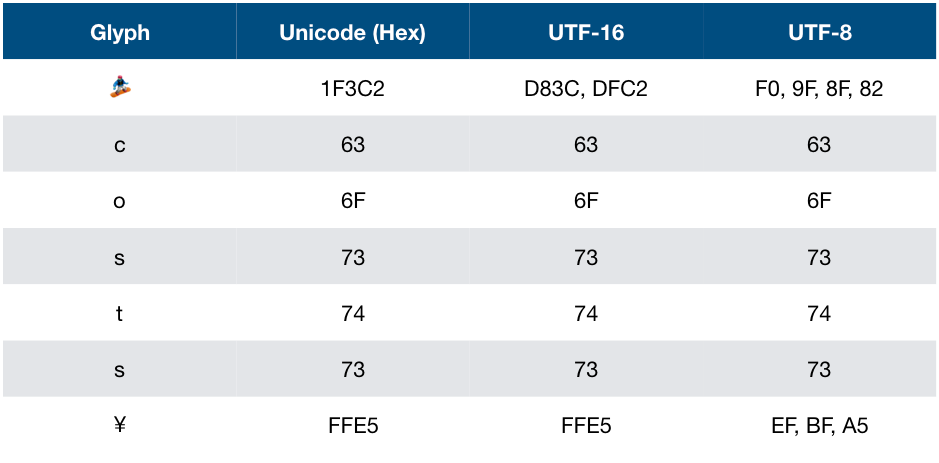
Back to the graph above, now we are focusing on the UTF-16 and UTF-8. You may notice that we use two 16-bit code units and four 8-bit code units to represent the 17-bit code point. How about encoding the smaller code point? We use less code units! The table below shows the facts that, for UTF-16 and UTF-8, the length of code units for encoding a code point are variable. This fact is very important, we’ll dig into this in the following section!
Now let’s go back to the modern era, to see how Swift works with the String type.
Unicode and Swift
Swift String type provides several Unicode-compliance API for working with various languages. In this section, we will introduce some handful Swift String APIs for dealing with Unicode or internationalization.
String Literal
In Swift, we can initialize a String by giving the code point directly. For example:
var stringLiteral = “\u{1F30A}” // "🌊"
or,
var stringLiteral2 = “\u{8702}\u{871c}\u{6ab8}\u{6aac}” // "蜂蜜檸檬"
UnicodeScalars
You can also convert a string to code points:
var scalars = “🌊”.unicodeScalars // 127754, or 0x1F30A
The unicodeScalars is a Collection of Unicode.Scalar, means that you can do loop over it, or use the map, filter on it. A Unicode.Scalar represents a code point in Unicode, excluding the surrogate code points, which are functional code points used by UFT-16. Swift also provides functions for getting the code units of different character encoding form. Based on what we learn in the previous section, we won’t be surprised to see the counts of code units vary among different encoding forms.
let snowboardCostYen = "🏂 costs ¥"
snowboardCostYen.unicodeScalars // count = 9
snowboardCostYen.utf16 // count = 10
snowboardCostYen.utf8 // count = 14
Grapheme Cluster
Generally, in Unicode, a character is represented by a single code point. But you can use more than one code point to represent a more complicated character. For example, the code point of an English character “e” is U+65. If we concatenate the U+65 with a acute code point U+301, we will get the e-acute character “é”:
let eCharacter = "\u{65}" // "e"
let graphemeCluster = "\u{65}\u{301}" // "é"
This kind of combination is called Grapheme Cluster. A grapheme cluster is made by variable-length code points. A typical example of this is Hangul, a Hangul character could be made by three different Jamos:
let first = "\u{1112}" // "ᄒ"
let second = "\u{1161}" // "ᅡ"
let third = "\u{11AB}" // "ᆫ"
let cluster = "\u{1112}\u{1161}\u{11AB}" // "한"
Grapheme cluster is not necessarily composed by two code points, you can append more marks to a normal character to make a more complicated character:
let enclose = “A\u{20DD}\u{301}” // A⃝́
How complicated would it be? Here is a scaring example of Zalgo:
var zalgo = "Z̫̫̳̰̦͙͙̒̇̽̒͗̑̂̋̚ạ͈̳̟̙͉̥̦̙̒̔̃͋̅͛̐l͕̯̟͖̣͊̓̒̂̑̽̊̃͑̃̓̽ḡ̟̲͚̞͆͊̋̏̽̏̉ͅô̤͈̩̖̞̙̲͚͍͓̘͉͂́̆"
If you check the code points of this string by printing zalgo.unicodeScalars, you may find that it’s made by five simple English characters, “Zalgo”, followed by a ton of combining marks. Currently, Swift supports the Extended Grapheme Clusters, you can check UNICODE TEXT SEGMENTATION for more detail.
Here’s another interesting fact of Swift string, let’s print the count for each of the example above:
let cluster = "\u{1112}\u{1161}\u{11AB}" // "한"
let enclose = “A\u{20DD}\u{301}” // A⃝́
print(cluster.count) // 1
print(enclose.count) // 1
Though the code points are more than one, the counts of those strings are still 1, which are consistent to the number of grapheme clusters in the string. Moreover, if you use a for loop to print the element of the string cluster, only one character “한” will be printed. All in all, in Swift, you can expect that the manipulation of the String type is as what you will see by human eyes.
Everything has two sides. To calculate the number of all grapheme clusters, we need to scan the whole string to determine which of those are clusters, which are not. Now you won’t be shocked if I say the time complexity of the .count API is O(n) in Swift, and there’s no random access to a Swift string!
Let’s keep this fact in mind, we’ll see more Swift String API related to this fact in the following section!
String API in Swift
String Index
Now we know that Swift String cannot be random access, then how do we access a specific character in a string? We can use the String.Index:
let snowboardCostsYen = "🏂 costs ¥"
print(snowboardCostsYen[8]) // Error!
let idx = snowboardCostsYen.index(snowboardCostsYen.startIndex, offsetBy: 8)
print(snowboardCostsYen[idx]) // "¥"
Using the Int subscript to a string infers random access, but using the String.Index subscript doesn’t. Even though the usage here looks complicated, the semantic meaning of this API is clear: be careful, the time complexity of getting the index is not O(1)!
It’s worth mentioning of some bight sides of the String API. Swift String provides many handful APIs for you. In .index(i:, offsetBy:) API, the offsetBy could be negative:
let head = snowboardCostsYen.index(snowboardCostsYen.startIndex, offsetBy: 2)
let tail = snowboardCostsYen.index(snowboardCostsYen.endIndex, offsetBy: -3)
let costSubstring = snowboardCostsYen[head...tail] // costs
The tail in above’s example indicates the third position from the end of string snowboardCostsYen, which is equivalent to snowboardCostsYen.index(snowboardCostsYen.startIndex, offsetBy: 6).
If you want to look up the index of a specific character, you can use:
let findIdxFirst = snowboardCostsYen.firstIndex(of: "¥")
let findIdxLast = snowboardCostsYen.lastIndex(of: "¥")
Those make the string index manipulation becomes very easy.
More detail about the String Index, especially for the design principle, check String Index Overhaul.
String Comparison
Back to character, it’s possible that two characters share the same glyph, while are composed by different code points. The e-acute “é” is a good example:
let acute1 = "\u{E9}" // "é"
let acute2 = "\u{65}\u{301}" // "é"
print(acute1 == acute2) // true
In this case, acute1 and acute2 look like the same, but the code points are different. If we compare those two string, Swift returns true. Again, Swift makes the API consistent with the natural result.
A special case is the English “A” and the Russian “А”:
*let* latinCapitalLetterA = “\u{41}” // "A"
*let* cyrillicCapitalLetterA = “\u{0410}” // "А"
print(latinCapitalLetterA == cyrillicCapitalLetterA) // false
Different from the e-acute case, these two characters are literally different, so it’s reasonable that Swift returns false.
Substring
From the example in the previous section:
let head = snowboardCostsYen.index(snowboardCostsYen.startIndex, offsetBy: 2)
let tail = snowboardCostsYen.index(snowboardCostsYen.endIndex, offsetBy: -3)
let costSubstring = snowboardCostsYen[head...tail] // costs
If you check the type of the costSubstring, you may find that it’s a Substring instead of a String. What’s the differences between String and Substring? In order to improve the performance of the String, when getting the substring from a string, Swift actually doesn’t allocate new memory space for the substring. Instead, it creates a range indicator, pointing out the range of the substring in the original string. The following graph depicts the relation:
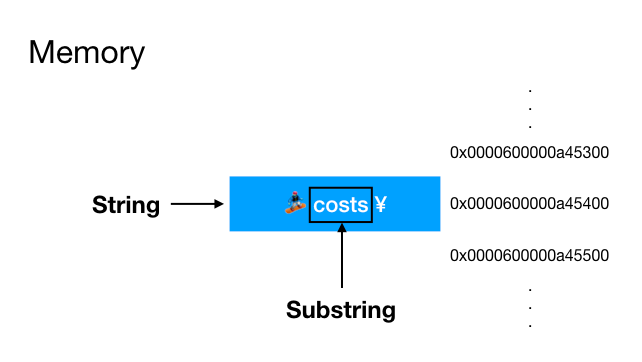
The blue rectangle in the memory space occupied by the original string. When we create a substring, a new range indicator will be created, as the black hollow rectangle upon the blue one. No new memory space is needed. By doing this, substring manipulation in Swift is very fast and efficient. Besides, both String and Substring conform to the StringProtocol, so the usage of Substring is almost the same with the String. 👍
Wait, you said the substring use the same memory space with the host string? So now two references are pointing to the same memory space? You bet! If you keep the reference to the Substring in somewhere else, the whole memory space of the original string will still be retained. As long as the substring reference is alive, space will be retained even when you remove the reference of the original string! Usually, Substring type is used as an intermediate. Means that it’s better to use the substring in a local scope, such as in a function or a closure, and release it once we don’t need it.
In swift-evolution, we can find more design mindset of the Substring.
String Performance
Similar to the Substring, the memory techniques are used for the copy of strings as well. Given a string, strA, we create a new string variable, strB, and assign the strA to the strB:
let strA = "string A"
var strB = strA
print(Unmanaged.passUnretained(strA as AnyObject).toOpaque()) // 0xbd0a6cb38041f74b
print(Unmanaged.passUnretained(strB as AnyObject).toOpaque()) // 0xbd0a6cb38041f74b
You will find that, even though the String is value type, they are sharing the same memory space! Now let’s make some tweaks on the strB:
strB.append("c")
print(Unmanaged.passUnretained(strB as AnyObject).toOpaque()) //0xbdc86da32414008a"
The memory address of the strB changed! Here Swift plays a trick called Copy-on-write. That is, if you’re just assigning the string to a new variable without any modification, they will all share the same memory space. It makes the copy of string very fast and space-efficient. On the other hand, the new memory space is allocated only when the string is going to be modified. In most cases, strings are copied without modification, there’s no point to allocate memory spaces if we are just reading them. This copy-on-write behavior works only behind the scenes, the interface behavior of a string remains the same as a value type.
NSString v.s. String
If you were born before 2014, or technically, you started writing iOS/macOS programs before 2014, you might be familiar with many NS-prefixed classes. Here we are going to discuss one of the NS-prefixed classes: NSString.
In Swift, a String could be just a Swift String, or it could be a NSString instance. Swift bridges the String and NSString, so you can simply use a type cast, “as”, to convert between those two types. Based on this, here’s a very interesting case:
let nStr: NSString = "🏂 costs ¥"
let sStr: String = nStr as String // Still NSString
let aNewStr = nStr + "" // aNewStr is a String now
In the beginning, we define a NSString, cast it to a String. Now the compiler treats this sStr as a String, though it’s still a NSString instance. By adding a “” by using “+” operator, aNewStr now is a String instance instead of a NSString instance. This observation is introduced by Ole Begemann in objc.io. This does matter because generally, the performance of a String instance is slightly better than the NSString instance.
Many of NSString methods do not be implemented in Swift String, but if you import the Foundation framework, you will have all the NSString methods bridged to the String type. The .components(separatedBy:) is an example:
import Foundation
let sStr = "🏂 costs ¥"
sStr.components(separatedBy: " ")
About the encoding logic, NSString is different from the String. The encoding logic of the NSString is on the UTF-16 point of view, while the String is Unicode-based. What does it mean? If we check the length of a String and a NSString:
let nStr: NSString = "🏂 costs ¥"
print(nStr.length) // 10
let sStr: String = nStr as String
print(sStr.count) // 9
The length of the sStr is 9, which is the same as the Unicode characters. But the length of the nStr is 10, which is the same with the number of UTF-16 code units. Specifically, the emoji “🏂” is encoded into two code units in UTF-16.
Although the Swift String is Unicode-friendly, practically, a string still needs to be encoded by a character encoding form to be stored in a computer system. In Swift 4, the String uses the UTF-16 (sometimes ASCII for small strings) as the character encoding form. Again, this behavior works seamlessly, you don’t even need to know how does Swift stores those values. All you need to memorize is that Swift String is Unicode-compliant, and that’s it.
Summary
In this article, we went through many aspects of the String type, including the character encoding, the API design, and the performance of it. Understand the character encoding is the key to the rationale of the Swift String API design. Swift is dedicated to making the usage of String intuitive and semantically clear. Besides, we also know that various techniques are adapted for improving the String’s performance. Thought the Swift API is still changing (it changed rapidly 😬), the logic and the mindset behind the API design should be the same. By knowing more implementation details of the Swift String, we are able to catch up the API changes and handle the String correctly in the future. 🍻
References
Strings and Characters — The Swift Programming Language (Swift 4.2)
Strings in Swift 4
Swift String Cheat Sheet